


اگر مهمترین سند قانونی ایالات متحده آمریکا یا قانون اساسی این کشور را وارد ابزارهای تشخیص متون کنید که برای تشخیص فعالیت هوش مصنوعی و چت باتهایی مانند: ChatGPT ساخته شده، این ابزار به شما اعلام میکند که قانون اساسی آمریکا تا احتمال ۹۶ درصد توسط هوش مصنوعی نوشته شده است؛ مگر اینکه جیمز مدیسون مسافر زمان باشد که درحال حاضر موضوع اصلی ما نیست.
چرا ابزارهای تشخیص متون به ما پاسخ های مثبت ولی غلط می دهند؟
امروزه، ابزارهای تشخیص متون موجب انتشار اخبار و مطالب جنجالی شدهاند که بخشی از آنها را پروفسورهای هیجان زدهای سهیم میشوند که به تمامی اعضای کلاس خود به دلیل استفاده از هوش مصنوعی شک دارند و حتی دانش آموزان و کودکان نیز پس از تمام کردن تکالیف و رایتینگهای خود به دلیل تقلب و استفاده از ChatGPT در دردسر میافتند.
ابزارهای تشخیص متون موجب شدهاند تا دانش آموزان و دانشجویان در برخی اوقات با بحران هویت مواجه شوند و معلمان و اساتید نیز که با روشهای تدریس توسعه یافته نسبت به چند دهه پیش روی کار آمدهاند، مجبور هستند تا با چنین مشکلاتی کنار بیایند و در کنار ارزیابی تسلط دانشجویان روی موضوعات تخصصی از طریق نوشتن مقاله یا انشاء، از نتیجه کار آنها استعلام بگیرند که آیا متن آنها توسط خودشان نوشته شده یا از هوش مصنوعی کمک گرفتهاند؟
استفاده از ابزارهای تشخیص متون اگرچه به اندازه کمک گرفتن از هوش مصنوعی شیرین و زیرکانه است، اما شواهد ثابت کردهاند که این ابزارها قابل اتکا نیستند. بنابر نتایج غلطی که از آنها دریافت شده، ابزارهایی مانند: GPTZero، ZeroGPT و حتی Text Classifier که توسط شرکت Open Ai توسعه یافته برای تشخیص مدلهای بزرگ زبان مانند: LLM ها و ChatGPT کاربردی نیستند.

بنابر تصویر بالا، اگر قسمتی از قانون اساسی آمریکا را وارد بخش ورودی ابزار GPTZeroکنید، به شما اطلاع میدهد که احتمال اینکه این متن توسط هوش مصنوعی نوشته شده باشد ۹۶ درصد است. در شش ماه گذشته، اسکرین شاتهای متعددی از نتایج سایر ابزارهای تشخیص متون در فضای مجازی، شبکههای اجتماعی و همچنین رسانه منتشر شده که اندکی گیج کننده و فکاهی است.
اینکه نویسنده قانون اساسی کشور آمریکا هوش مصنوعی بوده، تنها نمونه کوچکی از ابهامات است و این ابزار حتی به انجیل نیز رحم نکرده است. برای اینکه بفهمیم چرا این ابزارها به چنین اشتباهاتی مرتکب میشوند، باید ابتدا به نحوه کار آنها پی ببریم.
فهم مفاهیم ابزارهای تشخیص متون
ابزارهای مختلف تشخیص متون از روشهای یکسان، اما از منطق متفاوتی در فرایند کار خود استفاده میکنند.
مدلهای زبانی وجود دارند که روی متنهای گستردهای مانند: میلیونها رایتینگ تمرکز میکنند و علاوه بر این، مجموعهای از قوانین نیز برای تشخیص متن نوشته شده انسان و هوش مصنوعی برای آنها وضع میشود تا از طریق آنها آموزش ببینند.
به عنوان نمونه، قلب ابزار GPTZero متشکل از شبکه عصبی است که براساس مجموعه بزرگ و متنوعی از متون انسان و هوش مصنوعی و با تمرکز بر نثر روان انگلیسی آموزش دیده است. در مرحله بعد، سیستم برای ارزیابی متن و طبقه بندی آن از ویژگیهایی مانند: پیچیدگی و یا burstiness در ارزیابی و دسته بندی متون استفاده میکند.
در یادگیری ماشین، Perplexity یا پیچیدگی، یک معیار سنجش است و تعیین میکند متونی که در دسترس مدل زبانی قرار گرفته تا چه حد با آموزشها فرق میکند.
بنابراین، معیار پیچیدگی موضوعی است که حین نوشتن، به مدلهای زبانی مربوط میشود. مدلهای زبانی مانند ChatGPT در همان ابتدای کار از بهترین منبع خود یعنی دادههای آموزشی بهره میبرند و هرچقدر خروجی نتایج آنها به دادههای یادگیری نزدیک باشد، میزان پیچیدگی نیز کاهش مییابد.
در این بین، اگرچه انسانها نیز نویسندگان بی نظمی هستند، اما میتوانند با پیچیدگی کمتری بنویسند. علاوه بر این، متونی که در زمینه قانون و با سبک آکادمیک یا رسمی نوشته میشود دارای عبارات مشابهی است.
حالا بیایید ۲ مثال عادی و عجیب را مطرح کنیم. همه ما با وارد کردن “من یک لیوان …… میخواهم” با عبارات تکمیل شده ای مانند: آب، چای و قهوه در جای خالی مواجه شدهایم که براساس دادههای آموزشی مدلهای زبانی عادی است و پیچیدگی در این عبارت بسیار کمتر است.
در مثال دوم، جای خالی درنظر گرفته نشده و “من یک لیوان عنکبوت میخواهم” هم انسان و هم مدل زبانی را شگفت زده و گیج میکند. از اینرو، میزان پیچیدگی و گیج کردن این جمله بالا است. همانطور که در عکس پایین مشاهده میکنید، در مقابل ۳.۷ میلیون نتیجهای که روی موتور جستجوی گوگل برای ” من یک لیوان قهوه میخواهم” به نمایش درآمده، تنها یک مورد به عبارت “من یک لیوان عنکبوت” میخواهم ارتباط داده شد.
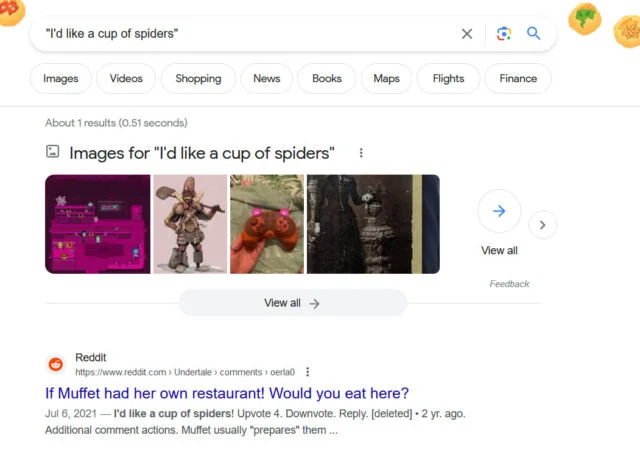
اگر زبان و نگارش بکار برده شده در بخشی از متن و براساس آموزشهای مدل، غافلگیر کننده نباشد، پیچیدگی پایین خواهد آمد. از اینرو، ابزارهای تشخیص متون، بیشتر به متن مورد نظر شک خواهند کرد و آن را به عنوان متن ساخته شده توسط هوش مصنوعی در نظر میگیرند. تمامی این توضیحات به آرامی ما را به سوژه جالب قانون اساسی آمریکا میرساند.
در واقع، سبک نوشتاری قانون اساسی آنقدر در این مدلها ریشه دوانده است که ابزارها آن را به عنوان متن هوش مصنوعی طبقهبندی میکنند و درصد تایید آنها بالا خواهد بود. Edward Tian که به عنوان سازنده GPTZero از او یاد میشود در رابطه با قانون اساسی آمریکا گفت:
قانون اساسی آمریکا به شکل مکرر به دادههای آموزشی بسیاری از مدلهای زبانی انتقال داده میشود. در نتیجه، موارد بیشتری از مدلهای بزرگ زبان آموزش دیدهاند تا متون مشابهی با قانون اساسی و سایر متون پر استفاده تولید کنند.
اما مشکل اصلی این است که نوشتن متون با پیچیدگی پایین برای انسانها میسر است و اگر جملاتی را با افعال، کلمات و سبک نوشتاری ساده بنویسیم، آشکار کردن واقعیت با مشکل مواجه میشود و طیف گستردهای از کاربران سردرگم خواهند شد.

یکی دیگر از ویژگیهای متن که توسط GPTZero مورد سنجش قرار میگیرد، “burstiness” است. burstiness به پدیدهای گفته میشود که در آن کلمات یا عبارات به شکل پشت سر هم ظاهر میشوند. در کل، burstiness تنوع و ساختار را در طول جمله و در سراسر متن ارزیابی میکند.
نویسندگان (انسان ها) از سبکهای پویایی در نوشتههای خود استفاده میکنند که در نتیجه، ساختار و طول جملات متنوع خواهد شد. به عنوان نمونه، ما این توانایی را داریم تا در کنار نوشتن و نگارش جملات بلند و پیچیده به نوشتن جملات کوتاه نیز بپردازیم، از تعداد زیادی از صفات در یک جمله استفاده کنیم و حتی در سایر متنها به آنها اشارهای کوچک نیز نکنیم. این تنوع یک خروجی طبیعی از خلاقیت انسان است که به خودانگیختگی نیز مرتبط است.
در مقابل نوشتههای انسانها، متنهای هوش مصنوعی بافتی پیوسته و رسمی دارد و یا حداقل در بعضی از موارد مشخص شده است. مدلهای زبانی نیز که در ابتدای قدمهای خود قرار دارند، جملات را با ساختار و طول مشابهی مینویسند. این کمبود تنوع باعث میشوند تا امتیاز Burstiness پایین، نمایانگر نوشته شده بودن متن توسط هوش مصنوعی باشد.
با این حال، burstiness یک معیار خطاناپذیر برای تشخیص محتوای هوش مصنوعی نیست و همانند perplexity، استثنائاتی نیز وجود دارد. ممکن است نویسنده به سبکی کاملاً ساختارمند و پیوسته بنویسد که در نتیجه نمره burstiness پایینی به دست میآورد.
برعکس، یک مدل هوش مصنوعی ممکن است به شکلی آموزش داده شود که جملات و ساختار آن بیشتر به انسان شبیه باشد و امتیاز Burstiness افزایش یابد. در واقع، مدلهای زبانی به شکل روزافزون بهبود مییابند و مطالعات نشان میدهد که متون آنها بیشتر شبیه نوشتههای انسان است.
در کل، هیچ فرمول جادویی برای ایجاد تمایز بین متون انسان و هوش مصنوعی وجود ندارد. اگرچه ابزارهای تشخیص متون میتوانند حدسهای قوی بزنند، اما حاشیه مشکلات، آنقدر زیاد است که برای نتایج دقیق نمیتوان به آنها اتکا کرد.
یک مطالعه که در سال ۲۰۲۳ و توسط محققان دانشگاه Maryland انجام شد، نشان داد که ابزارهای تشخیص متون در بسیاری از مواقع کاربردی نیستند و تنها میتوانند عملکرد بهتری را نسبت به الگوریتم طبقه بندی یادگیری ماشین داشته باشند.
Simon Willison، محقق هوش مصنوعی گفت:
به نظرم ابزارهای تشخیص متون همانند روغن مار هستند. همه انتظار دارند تا از این محصول به شکل جداگانه استفاده کنند. بااینکه فروش محصولی که همه خواهان آن هستند آسان است، اما در سمت دیگری از قضیه، تاثیر گذاری آن نیز از اهمیت بالایی برخوردار است.
علاوه بر این، مطالعه اخیر دانشگاه استنفورد نشان داد که ابزارهای تشخیص متون رابطه مثبتی با نویسندگان غیر انگلیسی زبان ندارند و متون آنها بیشتر از نویسندگان انگلیسی زبان به عنوان متن هوش مصنوعی تشخیص داده میشود.
هزینه اتهام اشتباه و تشخیص ابزارهای تشخیص متون

بعضی از افراد، مانند Ethan Mollick که در مدرسه Wharton کار میکند، از هوش مصنوعی استقبال میکند و حتی استفاده از ابزارهایی مانند: ChatGPT را برای یادگیری بهتر پیشنهاد میکند. به گفتهی او هیچ ابزار قابل اتکایی برای تشخیص نوشتههای بینگ، بارد و ChatGPT وجود ندارد و ابزارهای فعلی برای ChatGPT 3.5 طراحی شدهاند.
او همچنین به این موضوع اشاره کرد که این ابزارها به راحتی شکست میخورند و نرخ اشتباهات آنها بیشتر از ۱۰ درصد است. علاوه بر این، خود ChatGPT نیز نمیتواند ارزیابی کند که متن مورد نظر شما توسط هوش مصنوعی نوشته شده یا خیر.
در مصاحبه سایت Ars Technica با GPTZero، به نظر میرسد که این شرکت از اخبار و نارضایتی کاربران آگاه است و قصد دارد تا با جدایی از ابزار تشخیص متون Vanilla روی پروژهای عجیب کار کند.
او در ادامه گفت:
در مقایسه با ابزارهای تشخیص دهنده مانند: Turn-it-in، ما سعی داریم تا از ساخت چنین سرویسهایی فاصله بگیریم. نسخه بعدی GPT Zero ابزار تشخیص متون نخواهد بود و تنها به نشانه گذاری متونی که توسط انسان و یا هوش مصنوعی نوشته شده بسنده خواهد کرد تا به لطف معلم و دانش آموز، هوش مصنوعی تکامل یابد.
در ادامه، نویسنده این وبسایت از مدیر GPTZero پرسید که نظر او درباره استفاده از GPTZero برای متهم کردن دانش آموزان در آکادمیها چیست و او گفت:
ما نمیخواهیم مردم از ابزار ما برای تنبیه کردن فرزندانشان استفاده کنند. در عوض، بهتر است تا در حوزه آموزش، اتکا به چنین ابزارهایی در بین معلمانی که از هوش مصنوعی استقبال میکنند و یا نسبت به آنها علاقهای نشان نمیدهند کاهش یابد. ما باید فناوری و ابزارهای خود را برای جوامع عرضه کنیم تا با بازخوردهای آنها مواجه شویم و متوجه شویم که وضعیت در چه حال است.
با وجود اینکه مشکلات زیادی حول موضوع ابزارهای تشخیص متون مطرح شده و گریبان گیر کاربران است، اما GPTZero همچنان با بالیدن به عرضه این ابزار برای معلمان به فعالیت خود ادامه میدهد و با افتخار، فهرست دانشگاههایی را که از این ابزار استفاده میکنند را تبلیغ میکند.
علاوه بر این، تفاوت عجیبی بین هدف مشخص شده Tian به منظور عدم تنبیه دانش آموزان و خواسته او برای کسب درآمد با اختراعش وجود دارد. اما هرهدفی که باشد، استفاده از این ابزارها، تاثیر فاجعه باری را روی دانش آموزان میگذارد.
یکی از اخباری که در چند روز گذشته در آمریکا مطرح شد و بازتاب گستردهای را حول ابزارهای تشخیص متون داشت، متهم شدن یک دانش آموز به دلیل تقلب بود که براساس ابزار تشخیص متن مشخص شده بود. سپس، او مدرکی از آخرین تاریخچه جستجوهای خود منتشر کرد که اگرچه توانست بی گناهی خود را ثابت کند، اما استرس وارد شده به دانش آموز برای دفاع از خود موجب شد تا به او حمله عصبی وارد شود.
نوشته های هوش مصنوعی غیر قابل تشخیص هستند و ممکن است این وضعیت تا بعدها ادامه یابد
با مواجه شدن با نرخ بالای پاسخهای مثبت و غلط و همچنین درنظر گرفتن درصدهای بالا برای گویندگان و نویسندگان غیر انگلیسی، واضح است که علم تشخیص متون هوش مصنوعی، از خطا ناپذیری فاصله درازی دارد و این فاصله به این زودیها کوتاه نخواهد شد. انسانها میتوانند همانند ماشین بنویسند و این حالت برای هوش مصنوعی نیز صدق میکند.
هوش مصنوعی اینجا است تا بماند و اگر به شکل هوشمندانهای مورد استفاده قرار بگیرد، میتواند در زمینههای مختلفی پیشرفت کند. اگر معلم در حوزهای که دانش آموز درباره آن مینویسد تخصص داشته باشد، میتواند با مطرح کردن سوال دانش او را بسنجد و ارزیابی کند که تا چه حد درباره موضوعی که درباره آن نوشته میفهمد.
نوشتن تنها نمایش و ثابت کردن دانش نیست، بلکه بخشی از آن به نمایان کردن شهرت فرد مربوط میشود؛ از اینرو، اگر نویسندهای نتواند برای هر واقعیتی که در متن خود به آن اشاره کرده بایستد و از خود دفاع کند، از هوش مصنوعی و مهارتهای خود به درستی بهره نبرده است.































نظرات