
سلام میخواهیم درباره موضوعی صحبت کنیم که فکر کنم برای خیلی ها از جمله کسانی که با بازی های کامپیوتری سروکار دارند جالب باشه. چرا که در آخر این موضوع ما به دو چیز مهم پیمیبریم. ضمنا دوستان عزیز اگر موضوعی در ذهنتون بود و اطلاعاتی در مورد اون میخواستید در نظرات درخواست کنید، تا در صورت امکان در وبسایت خبری تکفارس قرار بدیم. با ما تا انتها همراه باشید.
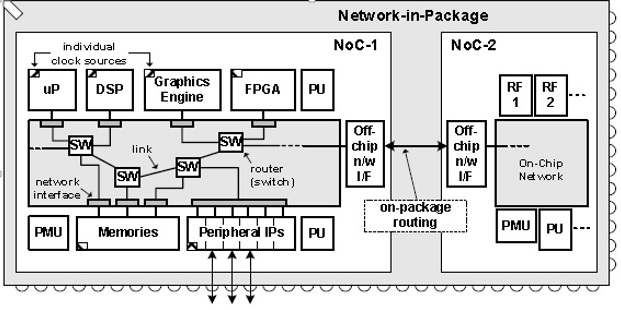
یک شبکه درون تراشه ای که از سیستم Packet-Switched استفاده میکند، برای بالا بردن کارایی پلتفرم های ناهمگن SOC طراحی و تولید شده است. این تراشه شامل چندین پردازنده، چندین حافظه، و دیگر ملزومات هوش ناهمگن و اتصال داخلی 51mW و سرعت ۱.۶ GHz در شبکه درون تراشه ای میباشد. یک شبکه درون تراشه ای برای بهینه سازی مصرف توان از موانع فعال جزئی، کدگذاری کم انرژی، و سیگنالینگ کم نوسان که در ادامه متن توضیح می دهیم استفاده میکند. شبکه مبتنی بر بسته( Network in Package) شامل ۴ NOC میباشد که برای ساختن نوع بسته ی ۶۷۶-BGA (یک نوع دستگاه شبیه ساز) استفاده شده است، این دستگاه برای شبیه سازی کارهای بزرگتر و سیستم های وسیع تر و نمایش دادن پردازش تصاویر ۲ بعدی و کارهای گرافیکی ۳ بعدی استفاده میشود.
تاخیر های درون تراشه
تاخیرهای ارتباطی درون تراشه ای بسیار مهم تر از تاخیر گیت های شناخته شده است و به تازگی مشکلات همزمان سازی بین مشخصه های هوش در رایانه خیلی بیشتر آشکار شده. حرکت در این مسیر تنها کار را بدتر میکند، مانند افزایش و کاهش بسامد زمان سنجی و مقدار ویژگی ها.
علاوه بر این ارتباطات داخلی، شامل زمان توزیع در تمام سطح تراشه، به سادگی تحت تاثیر پردازش های نامعلوم یا اختلالات فیزیکی قرار میگیرد. در این متن کارایی SOC ها (System on Chip ) محدود خواهد شد به توانایی آن برای موثر ساختن کارایی های از پیش تعیین شده و بازبینی IPS های قبلی و برای اصلاح کردن ملزومات ارتباطی آنها. یعنی این میتواند نحوه ارتباطات باشد تا اینکه تسلط بر محاسبات. علاوه بر این توان مصرفی در ارتباطات به بخش پر اهمیتی از توان سراسری سیستم به حساب میآید.
به تازگی، معماری شبکه های درون تراشه ای به صورت فزاینده، قابل اطمینان و بسیار مطلق در زیرساخت ارتباطات درون تراشه ای، نمایان شده اند.
معماری NOC از پروتکل های لایه ای و شبکه های Packet-Switched که شامل مسیریاب های درون تراشه ای و اتصالات و رابط های شبکه در یک توپولوژی از پیش تعریف شده میباشد، استفاده می کند. به عنوان مثال همانگونه که در شکل زیر نمایش داده شده، بجای اندازه گیری پردازش اتصالات داخلی، در بالاترین مرحله، از مسیریابی ویژه ی سیم های سراسری اختصاصی، که امروزه ثابت شده بهترین راه اتصال آنها با معماری On-Chip Packet Switching Network است استفاده شده است، که بسته ها را در میان IPS مسیریابی میکند. مزیت استفاده از سیستم NOC شامل هر دو آنها یعنی قابل اطمینان بودن و کارایی مفید است.
 تعداد زیادی از معماری ها و تئوری ها در مورد تراشه های NOC بررسی شده و وجود دارد. مانند طراحی اسلوب شناسی، اکتشاف جانمایی، ضمانت کیفیت سرویس، و جابجایی قابل اطمینان. فقط تعداد کمی از این ها توانستند بر روی تراشه و بدون اجرا تکمیل و وارسی شوند. برای جابجایی قابل اطمینان داده ها با هزینه پایین، توان مصرفی در زیرساخت شبکه باید به درستی به حداقل برسد.
تعداد زیادی از معماری ها و تئوری ها در مورد تراشه های NOC بررسی شده و وجود دارد. مانند طراحی اسلوب شناسی، اکتشاف جانمایی، ضمانت کیفیت سرویس، و جابجایی قابل اطمینان. فقط تعداد کمی از این ها توانستند بر روی تراشه و بدون اجرا تکمیل و وارسی شوند. برای جابجایی قابل اطمینان داده ها با هزینه پایین، توان مصرفی در زیرساخت شبکه باید به درستی به حداقل برسد.
در این کار ما یک NOC برپایه ی Star Connect را با تکنیک های مختلف توان مصرفی کم طراحی و اجرا کردیم. تراشه حاوی IPS های ناهمگن مانند ۲ پردازنده از نوع RISC، تعدادی حافظه، FPGA ،Off-Chip Network Interface و PPL 1.44 GHz میباشد. مدار مجتمع شبکه درون تراشه ای ۸۹.۶ Gb/s پهنای باند متراکم فراهم میکند و کمتر از 51mW در حالت فول ترافیک مصرف میکند. از طرف دیگر کارهای گذشته 264mW را برای فراهم کردن پهنای باند 51Gb/s مصرف میکردند. میزان استفاده توان برای فراهم کردن پهنای باند این کار نسبت به کار قبلی ۱۰ بار کاهش یافته. این طراحی در مورد تکنیک های توان مصرفی کم برای شبکه های درون تراشه ای ارائه شده و هدف را صحت میبخشد. SOC های مقیاس بزرگ با تراشه های عظیم از قبیل سیستم های منطقی حافظه ای تعبیه شده، بخاطر بازدهی پایین و مشکلات بالا بودن هزینه اغلب زیان میبینند.
NOC ها ساختار پیمانه ای شکل دارند که یک سیستم بزرگ می تواند به چندین قسمت یا تراشه تقسیم شود تا از این مشکلات بکاهد. در این کار، ۴ NOC برروی یک بسته برای نمونه سازی سیستم بزرگتر داریم تا یک NIP را شکل دهند. اتصالات تراشه به تراشه در یک بسته، برای تاخیر کم و بی ثباتی کم ارتباطات بیرون تراشه ای مقاومت کمی را به کار میاندازند.
مدارات و معماری NOC
برای طراحی Network-on-Chip، چیزهای زیادی وجود دارد که باید مشخص شود، از قبیل پروتکل ارتباطی، توپولوژی شبکه، روش راه گزینی، عمق بافر در روتر، روش همزمان سازی زمان، یک طرح علامت دهی و بعد ادامه میدهیم. در این قسمت بر اساس یک ایده ی ساده اما مهم، مختصری در مورد این که چه چیز مشخص میشود و نقش این ها در مراحل طراحی چیست ارائه خواهد شد.
توپولوژی ستاره ای سلسله مراتبی
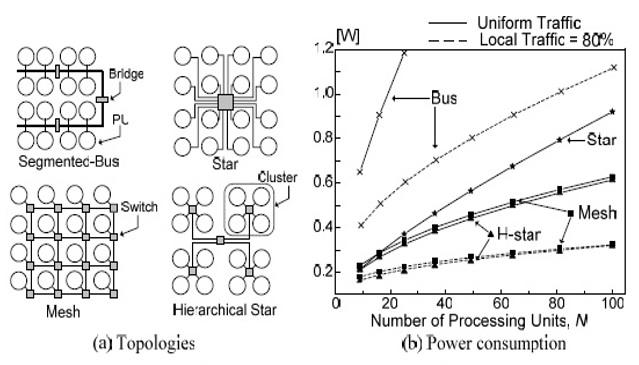
اولین مرحله برای طراحی ساختار NOC انتخاب مناسب ترین توپولوژی برای NOC است. در این کار ما توپولوژی هایی را که زیاد مورد مقایسه قرار گرفته اند مانندBUS ، Star ،Mesh ،H-Star، و توپولوژی های مبتنی بر میزان توان مصرفی، که به موضوع ما مربوط میشود را مورد مقایسه قرار دادیم. بر اساس یک تحلیل محاسباتی نمایش داده شده در شکل پایین، توپولوژی های H-Star و Mesh نه تنها کمترین میزان توان مصرفی را تحت تاثیر ترافیک یکنواخت نشان داده اند بلکه ترافیک را نیز متمرکز کرده اند. ما برای سیستم خود توپولوژی H-Star را انتخاب کرده ایم چون دارای ساختاری انعطاف پذیرتر بوده و Switching Hop های کمتری نسبت به توپولوژی Mesh دارد.
 همزمان سازی سراسری
همزمان سازی سراسری
تکنولوژی جدید SOC، یک سیستم پردازنده ی چند کاره ی ناهمگن است با مرجع های مختلف زمانی. به دلیل سختی همزمان سازی سراسری، پردازنده باید به خوبی پردازنده مرکزی باشد و مستقل عمل کند. برای از عهده برآمدن با دامنه های زمانی چندگانه، در این پیاده سازی هر واحد پردازش ساعت زمانی خودش را به کار میاندازد، اما آن پردازنده با یک ساعت منحصر به خود در ارتباط است. رابط شبکه مرجع زمانی را از ClkPu به ClkNet و برعکس تغییر میدهد.
ClkNet برروی تراشه همزمان سازی نشده، بنابراین ارتباطات ما بر اساس Mesochronous عمل خواهد کرد. یعنی با فرکانس هم شکل اما با اریب های متفاوت. برای ارتباطات Mesochronous، از طرح همزمان سازی منبع استفاده میکنیم، یعنی جایی که سیگنال آغاز انتقال داده در کنار بسته حرکت میکند. سیگنال آغاز انتقال داده به عنوان مرجع زمانبندی استفاده میشود، تا سالم رسیدن داده را در رسیدن به مقصد نهایی ضمانت کند.
پروتکل پیشنهادی NOC از دادوستد پشت سر هم و دو مرحله پشتیبانی میکند و از سرویس کلاس ها، یک بسته (Package)، یک هدر ۱۶ بیتی، ۳۲ بیت آدرس، و ۳۲ بیت مقدار داده که سریال بندی شده به کانال های ۸ بیتی برای کاهش محیط مجازی شبکه و توان مصرفی، تشکیل شده است.
تکنیک های مصرف کم توان
در این مدلسازی، تکنیک های کم مصرف قابل توجهی در لایه فیزیکی، لایه شبکه و لایه انتقال داده پیشنهاد شده است.
سیگنال های کم نوسان در اتصالات سراسری
لینک سویچ های متصل شده ی سراسری معمولا دارای طول کمی (میلیمتری) هستند. در نتیجه این از لتنسی های بالاتر و استفاده ی بیشتر از توان مصرفی نسبت به مقدار مصرفی که اتصالات محلی دارند جلوگیری میکند. ایجاد ارتباطات Cross-Chip بسیار هزینه بالایی خواهد داشت. سیگنال دهی کم نوسان می تواند به شکل خیره کننده ای مصرف انرژی را کاهش دهد، و افزایش نوسان سیگنال باعث افزایش تاخیر زمانی میشود. تصویر زیر تفاضل در اجرای سیگال دهی کم نوسان را نمایش میدهد. سیستم های سراسری به صورت زیگزالی آماده شده اند تا کار سیمی به بلندی ۵.۲ میلیمتر را بدون استفاده از تقویت کننده ی سیگنال انجام دهند. برای یافتن بهینه ترین نوسان ولتاژ، ما شبیه سازی Post-layout را با یک ظرفیت مشخص و دقیق و مدل مستحکم سیمی پی میگیریم. شکل b در تصویر زیر توان مصرفی را در یک فرستنده و یک گیرنده بر اساس Vswing نمایش میدهد. شکل c انرژی و تاخیر زمانی حاصله را نمایش میدهد. تاخیر زمانی از یک فرستنده به یک گیرنده حدودا ۰.۹ نانو ثانیه میباشد و نوسانات آن بر اساس Vswing یا برآورد سیگنال به کوچکی 40psec ± میباشد. همانطور که در شکل مشاهده میکنید ولتاژ نوسان بهینه، ۰/۴۵ V ۰/۴۰ ،V و ۰/۳۰ V به ترتیب در 400Mbps و 800Mbps و ۱.۶ Gbps نرخ سیگنال میباشد. در هر فرمان عملیاتی، میزان ولتاژ محرک برای میزان ولتاژ بهینه در بالاترین سطح بر اساس سیگنال دهی کم مصرف به دست آمده و اتلاف توان در اتصالات سراسری در مقایسه با Full Swing Repeated link به ۱/۳ کاهش یافته. همچنین تقویت کننده های توان سطحی بر روی سیستم ها وجود ندارند.
 فعال سازی جزئی خط عرضی
فعال سازی جزئی خط عرضی
تکنیک خط عرضی به صورت گسترده در Router ها به عنوان ساختار Switching استفاده میشود. به جهت کاهش توان مصرفی در خط عرضی ما تکنیک فعال سازی جزئی خط عرضی را پیشنهاد کردیم. این تکنیک توسط تعیین کردن بافرهای میانجی (Tri-State Buffers) و تسهیم کننده از فعالیت های غیر ضروری جلوگیری میکند. در نتیجه ۲۲% ذخیره توان در خط عرضی ۸*۸ بدست میآید.
رمزگزاری جریان ضعیف در اتصالات سریال درون تراشه ای
ارتباطات سریال همگام سازی شده ی منبع در ارتباطات موازی چند بیتی، در صورت های اریبی و مکالمه متقابل، هزینه بری محیط، دشواری سیم کشی و همزمان سازی ساعت مزایای بسیاری دارد. هرچند مراقبت از سیم های پی در پی در برابر پراکندگی، مقدار انرژی بیشتری از خط های موازی برای تسهیم بیت ها از بین میبرد. در این کار، ما روش جدید کدگذاری SiLENT را، برای کاهش انرژی مخابره شده از ارتباطات پی در پی با به حداقل رساندن تعداد انتقال ها بر روی سیم های سریال پیشنهاد کرده ایم.
این روش رمزگذاری میزان قابل توجهی از توان ارتباطات را برای کاربردهای چندرسانه ای حفظ میکند. این روش ۷۷% از انرژی را برای دستورات دسترسی به حافظه و ۴۰~۵۰% از انرژی یا توان را برای برنامه های کاربردی گرافیکی سه بعدی کاهش میدهد.
مقیاس گذاری فرکانس عملیاتی
سیستم PPL، ساعت های داخلی مانند ساعت MHz 100 برای گروه اصلی PU ها، ساعت ۵۰ MHz برای واحدهای گروهی جانبی و یک ساعت شبکه ۱.۶ GHz برای سویچ ها و واسط های شبکه را تولید میکند. فرکانس های ساعت برای مدل های مدیریت توان یا انرژی قابل تنظیم هستند. یعنی ۱۰۰\۵۰\۱۶۰۰ MHz برای مدل سریع و ۵۰\۲۵\400MHz برای مدل کند.
بعد از معرفی تکنیک های پایین آوردن توان مصرفی به طراحی و پیاده سازی تراشه میپردازیم.
اصول و روند طراحی
شبکه های درون تراشه ای به طرز سفارشی شده طراحی میشوند:
پردازنده های مجتمع به هم آمیخته، حافظه های کامپایل شده توسط کامپایلر SRAM و شبکه های درون تراشه ای برای مصرف توان پایین تر و کارایی بالاتر به صورت کاملا سفارشی هستند. پردازنده ها و حافظه ها از خرده فروش خریداری شده و دوباره به صورت متصل به واسط های شبکه و بسته بندی استفاده میشود. تصویر زیر روند طراحی را نمایش میدهد، و ابزار EDA، مراحل طراحی و خروجی های قابل تحویل در هر مرحله را به نمایش میگذارد. برای تیم ما این کار حدودا ۶ ماه طول کشید.

پیاده سازی تراشه
با ساختار معماری پیشنهاد شده NOC و پروتکل و تکنیک های توان مصرفی کم، ما یک SOC چند رسانه ای را به عنوان نمونه اولیه ارائه کردیم. نمودار کلی در شکل ۱ نمایش داده شده.
 تراشه از دو گروه درست شده است. یک گروه اصلی و یک گروه جانبی. گروه اصلی شامل دو پردازنده RISC و EPGA درون تراشه ای، دو حافظه 64Kb SRAM، و یک درگاه خارج تراشه ای میباشد. دو پردازنده RISC از سیستم های چند پردازنده تقلید میکنند. درگاه خارج تراشه ای (OGW) ارتباطات برون تراشه ای یکپارچه را با NOC های دیگر در بسته های یکسان فراهم کرده یا به عنوان سکو برای ساختن سیستم های با مقیاس بزرگتر عمل میکند. با استفاده از OGW، یک PU در یک قطعه میتواند با PU های دیگر در قطعات دیگر بدون تبدیل کردن پروتکل ارتباط برقرار کند.
تراشه از دو گروه درست شده است. یک گروه اصلی و یک گروه جانبی. گروه اصلی شامل دو پردازنده RISC و EPGA درون تراشه ای، دو حافظه 64Kb SRAM، و یک درگاه خارج تراشه ای میباشد. دو پردازنده RISC از سیستم های چند پردازنده تقلید میکنند. درگاه خارج تراشه ای (OGW) ارتباطات برون تراشه ای یکپارچه را با NOC های دیگر در بسته های یکسان فراهم کرده یا به عنوان سکو برای ساختن سیستم های با مقیاس بزرگتر عمل میکند. با استفاده از OGW، یک PU در یک قطعه میتواند با PU های دیگر در قطعات دیگر بدون تبدیل کردن پروتکل ارتباط برقرار کند.
گروه جانبی دارای ۳ حافظه برای تقلید واحدهای جانبی است. هر ۲ گروه توسط اتصال سراسری 5mm به یکدیگر متصل هستند که از سیگنال دهی کم نوسان استفاده میکنند تا مصرف توان را کاهش داده و همچنین تفاضل سیگنال دهی برای SNR بالاتر را کاهش دهند.
PLL ساعت های قابل تنظیم را برای PU ها و شبکه ها تولید میکند.
ساعت های PU با یکدیگر برای نمونه سازی یک سیستم با مرجع های زمانی مختلف همگام نشده اند. به همین دلیل برای کاهش نامتوازنی ساعت هیچ تلاشی لازم نیست. شبکه درون تراشه ای از ۳/۲ گیگابایت در ثانیه پهنای باند ارتباطی برای هر PU و ۱۱.2GB/s پهنای باند متکرام در حالت سریع (FAST MODE) پشتیبانی میکند. تراشه با استفاده از پردازش ۰.۱۸ CMOS با لایه های فلزی ۶-AL و سطح قطعه ۵*۵ میلیمتر پیاده سازی میشود.
شکل ۲ تصویر قطعه را نمایش میدهد.
 شبکه درون تراشه ای توان 51mW در حالت سریع و در وضعیت ترافیک سنگین مصرف میکند.
شبکه درون تراشه ای توان 51mW در حالت سریع و در وضعیت ترافیک سنگین مصرف میکند.
شکل سمت راست کم شدن مصرف توان و سودمندی پیشنهاد تکنیک های کم توان را با استفاده از تکنیک های پیشنهادی مانند سیگنال دهی کم نوسان، فعال سازی جزئی خط عرضی، و کدگزاری پیوندهای پی در پی، نشان میدهد که مصرف توان سراسری ۴۳% کاهش دارد.
شبکه های مبتنی بر بسته
همانطور که در شکل ۳(d),(c) مشاهده میکنید، ۴ NOC بر روی ۱ بسته ۶۷۶-BGA نصب شده است.
Network in Package به ۴ منبع تغذیه نیاز دارد:
۱.8V برای منطق دیجیتالی
۱.8V برای مدار آنالوگ
۳.3V برای I/O یا Input / Output
۰.5V برای پیوندهای کم نوسان
فرکانس های عملیاتی برای هر ماژول متفاوت است:
50MHz برای منطق جانبی، 100MHz برای پردازنده ها، 800MHz برای زمانبد، و ۱.6GHz برای شبکه های درون تراشه ای.
 یک موضوع مهم برای طراحی بسته، تمامیت توان است، یعنی یک طراحی از توان و عنوان (P/G) شبکه، در نقشه ی (P/G) از بسته در فرکانس عملیاتی هیج مشکل مهمی نباید رخ دهد.
یک موضوع مهم برای طراحی بسته، تمامیت توان است، یعنی یک طراحی از توان و عنوان (P/G) شبکه، در نقشه ی (P/G) از بسته در فرکانس عملیاتی هیج مشکل مهمی نباید رخ دهد.
در غیر این صورت یک نویز کوچک از سیگنال ها یا سیستم های خارجی، نویز (P/G) قابل توجهی را که باعث بی ثباتی در شبکه (P/G) میشود را به وجود میآورد. برای تحلیل درست تمامیت توان، ما از روش های Transmission Line Matrix و Simultaneous Switching Noise Analyses استفاده میکنیم. به شکل ۳(a),(b) نگاه کنید. ما خازن های یکپارچه ای را برای ولتاژ توان در موقعیت مناسب: ۵ برای توان منطقی، ۲ برای توان I/O و ۱ برای توان آنالوگ درست کرده ایم. هر خازن دارای 10nf ظرفیت الکتریکی و 600PH رشته مؤثر مقاومت خواص است. شکل ۷(a) مقاومت نقشه توان را نمایش میدهد. ما مقاومت را ۱Ω در نظر گرفتیم. خط چین برای آشکار سازی نقشه (P/G) و نقطه چین برای درج خازن های جدا از هم پیشنهاد شده است. مقاومت سطح آشکار شده القا ویژگی ها و تخطی کردن مقاومت هدف در 800MHz و ۱.6GHz را نشان میدهد. بعد از درج خازن های جدا از هم، در ۲۷۲.1MHz از L در سطح آشکار شده و C از خازن های درج شده تشدید مقاومت رخ داد. از این رو مقاومت در سطح مورد نظر از ۱Ω کمتر شد. شکل ۳(b) نتیجه تحلیل SSN را زمانی که تحت تاثیر ۱.6GHz سیگنال ورودی قرار میگیرد نمایش میدهد. سویچینگ نویز از 34mV به 2mV به دلیل درج خازن های جدا ازهم، در بسته و در سطح کاهش پیدا کرده. ما همچنین خطوط اتصال به زمین را برای رفع سیگنال های ناخواسته بین خطوط سیگنال های پرفرکانس درج کردیم.
سنجش و اثبات سیستم
نتیجه سنجش
تراشه ی تکمیل شده با موفقیت آزمایش شد. شکل ۴(b) سنجش بسته ها را با و بدون پیشنهاد کدگذاری Silent، به ترتیب زمانی که یک نرم افزار کاربردی گرافیکی سه بعدی در حال اجرا شدن در سیستم است نمایش میدهد. بعد از کدگذاری، انتقال روی یک کانال از ۱۳۴ به ۷۹ کاهش یافته است.
 اثبات سیستم
اثبات سیستم
ما یک سیستم عملیاتی را با اجرای شبکه های مبتنی بر بسته برای نرم افزارهای کاربردی چندرسانه ای توسعه دادیم. شکل ۵ اثبات سیستم را که شامل NIP-Board در بالا و Video Board در لایه پایینی، ماژول LCD میشود را نمایش میدهد. سیستم پردازش تصویر و پردازش انیمیشن بر روی صفحه نمایش از طریق شبکه های روی تراشه و شبکه های مبتنی بر بسته را نشان میدهد. همچنین شکل ۵ نقل و انتقال بسته ها بین ۲ NOC روی NIP، جایی که ۲ NOC در حال اجرا با فرکانس های زمانی متفاوت هستند را نمایش میدهد. یعنی 400MHz و 274MHz.
 نتیجه
نتیجه
کاهش توان مصرفی توسط به کارگیری چندین تکنیک از قبیل سیگنال دهی کم نوسان، فعال سازی جزئی خط عرضی، کد گذاری ارتباط سریالی کم انرژی، و سنجش فرکانس زمانی به دست آمد. تراشه حاوی ۲.۵ میلیون تراتزیستور بوده و کمتر از 160mW مصرف میکند و شبکه درون تراشه ای کمتر از 51mW مصرف کرده و ۱۱.2GB/s پهنای باند شبکه متراکم فراهم میکند. تراشه ۵*۵ میلیمتری پردازش CMOS 0.18µm را تقلید کرده و با موفقیت شمرده می شود و روی یک سیستم شبکه مبتنی بر بسته اجرای نرم افزارهای کاربردی چندرسانه ای را به خوبی اثبات میکند.
همانطور که در آغاز این موضوع گفته شد، ما به ۲ چیز مهم پی می بریم.
اول اینکه استفاده از این تکنولوژی به طور چشمگیری هزینه ی ساخت قطعات را پایین آورده و توان انرژی مصرفی را کاهش و از ایجاد گرمای زیاد روی تراشه جلوگیری میکند. همچنین با افزایش پهنای باند، خصوصا هنگام بالا بودن ترافیک از بروز مشکلی همچون گلوگاه شدن اطلاعات جلوگیری میشود.
دومین چیزی که ما به آن پی میبریم آن است که، کمپانی بزرگ AMD برای محصولات خود از زمان معرفی کارت های گرافیک سری R9 از این تکنولوژی بسیار استفاده کرده و در آینده نیز استفاده خواهد کرد. تکنولوژی هایی مانند Tress FX که مربوط به بافت های مو در بازیهای کامپیوتری و تکنولوژی Tessellation که در مقالات آینده در مورد آن بحث خواهیم کرد نیاز به یک تراشه ای قدرتمند داشتند که System on Chip این کار را برای AMD انجام داد. یکی از دلایل پایین تر بودن قیمت محصولات AMD نسبت به رقیب قدرتمند خود Nvidia نیز همین موضوع میباشد. توسط این تکنولوژی AMD توانست این شعار را واقعیت ببخشد. ادغام CPU و GPU که APU را تشکیل میدهد. با ما در مقالات آینده همراه باشید.

























دیدگاه ها